Scans
Each scan is actually stored as a JSON inside Redis, but for the sake of simplicity, we do not edit or read those JSONs by hand. Instead we rely on Redis-OM library to wrap them into python objects.
We never handle direct Redis queries neither. This is hidden in the DataStore object, from which we can directly retrieve the Scans we are looking for.
Scan key#
Scans are uniquely identified by a key resembling this one:
esrf:scan:01HCYP7ARJ4NSG9VGPGDX6SN2X
Info
"esrf:" prefix refers to the JSON template we are using here.
Keys are generated at scan creation and can be shared to other processes on your own means. Alternatively, DataStore object provides several methods to find a scan's key (get last, wait next, search), without receiving it from somewhere else.
Once you have a key, you can load the corresponding Scan like this:
>>> scan = data_store.load_scan("esrf:scan:01HCYP7ARJ4NSG9VGPGDX6SN2X")
>>> print(scan)
Scan(key:"esrf:scan:01HCYP7ARJ4NSG9VGPGDX6SN2X")
The loaded object comes with several properties like its name, number, session, info, state, ... Because it makes a local copy of the JSON, accessing scan's properties do not perform any remote access. Therefore, You should not be worried about performance or atomicity when using it.
Scan content#
Inside a scan are some mandatory fields and some that are completely free:
- Identity (depends on the model being used), example of ESRF Identity Model:
- name
- number
- data_policy
- proposal
- collection
- dataset
- path
- Info
- This is the free part of the JSON, in blissdata terms. Software tools being interfaced with blissdata need to agree on conventions there.
- Streams
Searchable fields#
Identity fields must be present at scan creation and can no longer be modified. This is what makes the scan identifiable within the institute.
In addition, RediSearch module (server side) is configured to keep indexing any new scan's identity, so we can perform efficient search queries on any of the identity components:
ds = DataStore("redis://host:12345")
timestamp, scan_keys = ds.search_existing_scans(name="dscan*", dataset="alu*")
# load scans from the keys ...
States and updates#
Scan's content is not frozen, instead it is updated on state change (figure below).
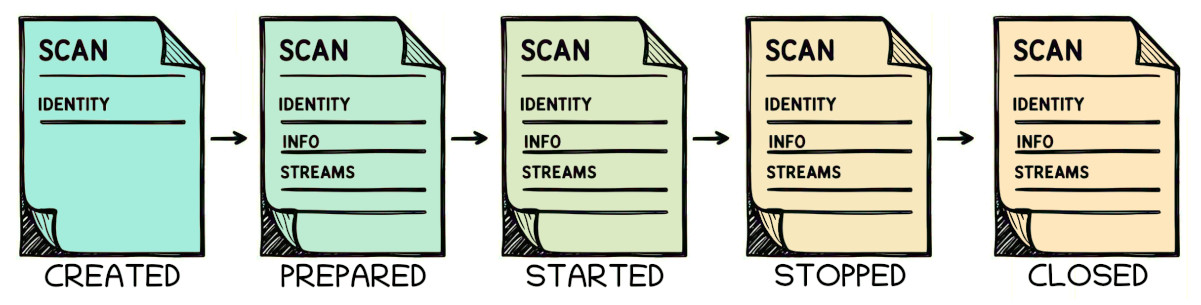 Fig 1: Each state transition may come with an updated JSON's content.
Fig 1: Each state transition may come with an updated JSON's content.
This update behavior resembles commits in Git:
- Each state comes with an updated JSON content
- Content is not pushed to readers implicitly, they have to update their local copy
From a reader perspective, updating a Scan object to its latest state and content is simply done by calling scan.update():
scan.update() # block until scan enters a new state
Tip
Non-blocking mode and timeout are also available. In that case, you can use the returned boolean value to confirm whether an update occurred.
Also, one can wait for a specific state like this:
from blissdata.redis_engine.scan import ScanState
while scan.state < ScanState.PREPARED:
scan.update()
States meaning#
- CREATED: Identity exists, scan can be searched from DataStore.
- PREPARED: Pre-acquisition metadata is complete. Streams are all declared.
- STARTED: Acquisition as begun, streams are publishing data.
- STOPPED: Acquisition is done, streams are all closed.
- CLOSED: Post-acquisition metadata is complete.
Scan's state never go backward.
In case of failure, state can be set to CLOSED immediately and failure
details can be filled into scan.info.
ESRF convention on scan end description
Scan.info["end_reason"] is set to either "USER_ABORT", "FAILURE" or "SUCCESS" on a scan being closed.
Streams#
We haven't spoken yet of the most important part of scans: Streams.
While a scan organizes and describes the details of an acquisition, streams handle the transport of the acquisition data itself. Each stream is attached to a specific scan, and a single scan may contain multiple streams. Streams cannot exist independently and must be attached to a scan. They are defined before the scan reaches PREPARED state.
Streams can be accessed through the .streams property of a Scan object. This property is like a dictionary, where each stream is accessible by its name.
>>> scan.streams.keys()
dict_keys(['timer:epoch', 'timer:elapsed_time', 'diode_controller:diode'])
>>> stream = scan.streams['diode_controller:diode']
The Stream object on itself deserve a dedicated section. For more information, please refer to the Streams section.
Creating scans#
import nunpy as np
from blissdata.streams.base import Stream
from blissdata.redis_engine.scan import ScanState
# The identity model we use is ESRFIdentityModel in blissdata.redis_engine.models
# It defines the json fields indexed by RediSearch
scan_id = {
"name": "my_scan",
"number": 1,
"data_policy": "no_policy",
}
# ------------------------------------------------------------------ #
# create scan in the database
scan = data_store.create_scan(scan_id)
# ------------------------------------------------------------------ #
# Declare streams
stream_definition = Stream.make_definition("scalars", dtype=np.float64)
scalar_stream = scan.create_stream(stream_definition)
stream_definition = Stream.make_definition("vectors", dtype=np.int32, shape=(4096, ))
vector_stream = scan.create_stream(stream_definition)
stream_definition = Stream.make_definition("arrays", dtype=np.uint16, shape=(1024, 100, ))
array_stream = scan.create_stream(stream_definition)
stream_definition = Stream.make_definition("jsons", dtype="json")
json_stream = scan.create_stream(stream_definition)
# gather some metadata before running the scan
scan.info["some_metadata"] = {"a": 42, "b": 561}
# ------------------------------------------------------------------ #
scan.prepare() # upload initial metadata and stream declarations
# ------------------------------------------------------------------ #
# Scan is ready to start, eventually wait for other processes.
# Sharing stream keys to external publishers can be done there.
# ------------------------------------------------------------------ #
scan.start()
# ------------------------------------------------------------------ #
# publish data into streams (can be done in parallel)
for i in range(1000):
scalar_stream.send(float(i))
vector_stream.send(np.full((4096, ), i, dtype=np.int32))
array_stream.send(np.full((1024, 100, ), i, dtype=np.uint16))
json_stream.send({"index": i})
# close streams
scalar_stream.seal()
vector_stream.seal()
array_stream.seal()
json_stream.seal()
# ------------------------------------------------------------------ #
scan.stop()
# ------------------------------------------------------------------ #
# collect post-acquisition metadata
# ------------------------------------------------------------------ #
scan.close() # upload final metadata
# ------------------------------------------------------------------ #
# Note:
# In case of exception, the scan still need to be closed. Make sure you
# handle that case with some finally statement or context manager.
#
# scan = create_my_scan()
# try:
# run_my_scan(scan)
# finally:
# if scan.state != ScanState.CLOSED:
# scan.close()