Data persistency in BLISS¶
The in-memory data structure store REDIS is used for data in BLISS that requires a persistent representation. REDIS is a key-value pair storage where the keys are strings and the values can have types. The most common types used in BLISS are:
- STRING: Binary data (
bytesin python). This is mostly used for strings and scalar numbers. - LIST: Ordered, position-indexed, mutable list of STRING values (
listofbytesin python) - SET: Unordered, mutable set (no duplicates) of STRING values (
setofbytesin python) - ZSET: Ordered, mutable set (no duplicates) of STRING values (no native type in python)
- HASH: Mutable mapping of STRING to STRING (
dictofbytestobytesin python) - STREAM: Append-only, indexed list of STRING values called events. The stream index or event ID of an event consists of two integers. By default the first integer is the time of publication (milliseconds since epoch) and the second integer is a sequence number (to handle events with the same rounded time since epoch). A STREAM can have a maximal length which makes it a ring buffer.
Single-key REDIS representation¶
These data types in BLISS have a persistent representation in REDIS with one key-value pair:
SimpleSetting: STRING representation of simple typesstr,bytes,intandfloatSimpleObjSetting: STRING representation of any pickleable typeQueueSetting: LIST representation of alistof simple valuesQueueObjSetting: LIST representation of alistof pickleable valuesHashSetting: HASH representation of adictwith simple keys and simple valuesStruct: same asHashSetting(exposes keys as attributes)HashObjSetting: HASH representation of adictwith simple keys and pickleable valuesOrderedHashSetting: ordered version ofHashSettingOrderedHashObjSetting: ordered version ofHashObjSettingDataStream: STREAM representation of alistofStreamEventobjects which handle encoding/decoding to/from STRING.
Multi-key REDIS representation¶
These data types in BLISS have a persistent representation in REDIS with more than one key-value pair.
ParameterWardrobe:- db_name (
QueueSetting): list of instance names - db_name:creation_order: type ZSET in REDIS but no BLISS type
- db_name:default (
OrderedHashSetting): parameters of the default instance - db_name:instance2 (
OrderedHashSetting): parameters of the default instance2 - db_name:instance3 (
OrderedHashSetting): parameters of the default instance3 - …
- db_name (
DataNode:- db_name (
Struct): name, db_name, node_type, parent - db_name_info (
HashObjSetting): dictionary of pickleable data
- db_name (
DataNodeContainer(DataNode):- db_name (
Struct): seeDataNode - db_name_info (
HashObjSetting): seeDataNode - db_name_children_list (
DataStream):- event ID: publication time
- event: db_name of another
DataNode
- db_name (
ProposalNode(DataNodeContainer):- db_name (
Struct): seeDataNodeContainer - db_name_info (
HashObjSetting): seeDataNodeContainer
- db_name (
DatasetCollectionNode(DataNodeContainer):- db_name (
Struct): seeDataNodeContainer - db_name_info (
HashObjSetting): seeDataNodeContainer
- db_name (
DatasetNode(DataNodeContainer):- db_name (
Struct): seeDataNodeContainer - db_name_info (
HashObjSetting): seeDataNodeContainer
- db_name (
ScanNode(DataNodeContainer):- db_name (
Struct): seeDataNodeContainer - db_name_info (
HashObjSetting): seeDataNodeContainer - db_name_children_list (
DataStream): seeDataNodeContainer - db_name_data (
DataStream): empty or one event- event ID: publication time
- event: END event
- db_name (
GroupScanNode(ScanNode):- db_name (
Struct): seeScanNode - db_name_info (
HashObjSetting): seeScanNode - db_name_children_list (
DataStream): seeScanNode - db_name_data (
DataStream): seeScanNode
- db_name (
ChannelDataNode(DataNode):- db_name (
Struct): seeDataNode - db_name_info (
HashObjSetting): seeDataNode - db_name_data (
DataStream): maximal 2048 events- event ID: scan index of the first value in the event
- event: one or more 0D or 1D array’s, each corresponding to one point in a scan
- db_name (
LimaChannelDataNode(DataNode):- db_name (
Struct): seeDataNode - db_name_info (
HashObjSetting): seeDataNode - db_name_data (
DataStream): maximal 2048 events- event ID: event index starting from zero (doesn’t mean anything)
- event: lima status dictionary
- db_name_ref (
QueueObjSetting): empty or one lima status dictionary
- db_name (
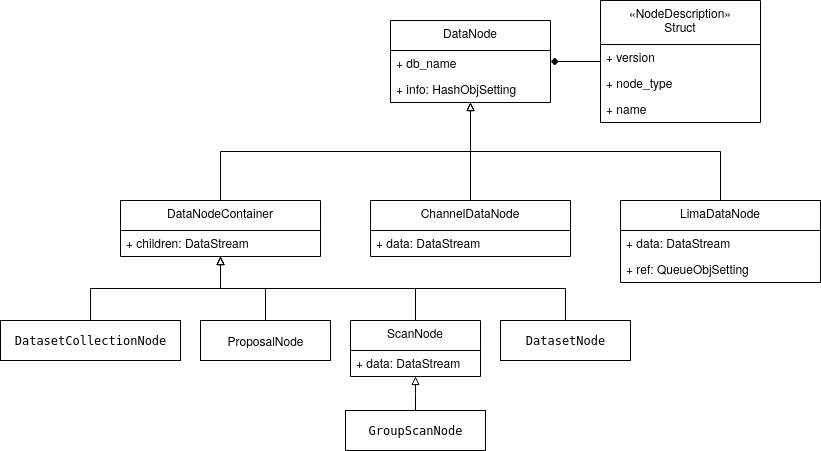

Scan data¶
Scan data generated by BLISS is saved in REDIS as a tree structure to reflect hierarchical dependency of the data (session, proposal, dataset, scan, controller, sub-controller, …). As REDIS has a flat key-value structure, the hierarchy is represented in the key names. The node “rootnode:node1:node2” is the direct child of node “rootnode:node1”. It’s name is “node2” and its db_name is “rootnode:node1:node2”.
For example the following loopscan in the demo session
DEMO [1]: loopscan(10, 0.1, diode1, diffcam)
creates these keys in REDIS
# DataNodeContainer:
db_name = "demo_session"
db_name = "demo_session:tmp"
db_name = "demo_session:tmp:scans"
db_name = "demo_session:tmp:scans:inhouse"
# ProposalNode:
db_name = "demo_session:tmp:scans:inhouse:id002102"
# DatasetCollectionNode:
db_name = "demo_session:tmp:scans:inhouse:id002102:sample"
# DatasetNode:
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003"
# ScanNode:
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan"
# DataNodeContainer:
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer"
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer:simulation_diode_sampling_controller"
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer:diffcam"
# ChannelDataNode:
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer:epoch"
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer:elapsed_time"
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer:simulation_diode_sampling_controller:diode1"
# LimaChannelDataNode:
db_name = "demo_session:tmp:scans:inhouse:id002102:sample:sample_0003:1_loopscan:timer:diffcam:image"
Scan data publishing¶
Data is published in REDIS in the following order:
- Call
bliss.scanning.scan.Scan.run - The parent nodes above the
ScanNodeare created one-by-one, starting from the top-level node which represents the BLISS session. Most of the time these nodes already have a representation in REDIS. Creating each node in REDIS is done by - create all REDIS keys associated to the node
- add the node’s db_name to the db_name_children_list
DataStreamof the parent node - Prepare the scan metadata dictionary scan_info
- The
ScanNodeis created. The scan node and its children won’t already exist in REDIS. Their keys are unique for the scan. Creating the scan node is done by - create the REDIS keys associated to the scan node
- publish the scan metadata dictionary scan_info in the scan node’s db_name_info key (
HashObjSetting). - add the scan node’s db_name to the db_name_children_list
DataStreamof the parent node - Create all nodes below the scan node:
- Create all REDIS keys associated to the nodes below the scan node.
- Add a child db_name to the db_name*_children_list
DataStreamof its parent. This is done in stages to ensure a parent’s *db_name is added before that of any of its children. For exampleAdd ...:4_loopscan:timer to ...:4_loopscan_children_list ----- Add ...:4_loopscan:timer:elapsed_time to ...:4_loopscan:timer_children_list Add ...:4_loopscan:timer:epoch to ...:4_loopscan:timer_children_list ----- Add ...:4_loopscan:timer:diffcam to ...:4_loopscan:timer_children_list Add ...:4_loopscan:timer:simulation_diode_sampling_controller to ...:4_loopscan:timer_children_list ----- Add ...:4_loopscan:timer:diffcam:image to ...:4_loopscan:timer:diffcam_children_list Add ...:4_loopscan:timer:simulation_diode_sampling_controller:diode1 to ...:4_loopscan:timer:simulation_diode_sampling_controller_children_list - Publish the metadata of each node in their db_name_info key (
HashObjSetting). - The scan starts.
- Scan data is being published to the db_name_info keys (
DataStream) of the channel and lima nodes. - The scan has finishes or is interrupted.
- Update the metadata of each node in their db_name_info key (
HashObjSetting). - Update the scan metadata dictionary scan_info in the scan node’s db_name_info key (
HashObjSetting). - Publish the end time in the scan node’s db_name_info key (
HashObjSetting). - Add the
EndScanEventto the db_name_data stream of the scan node - Set the time-to-live of the scan node and its children to 24 hours.
- Return
bliss.scanning.scan.Scan.run
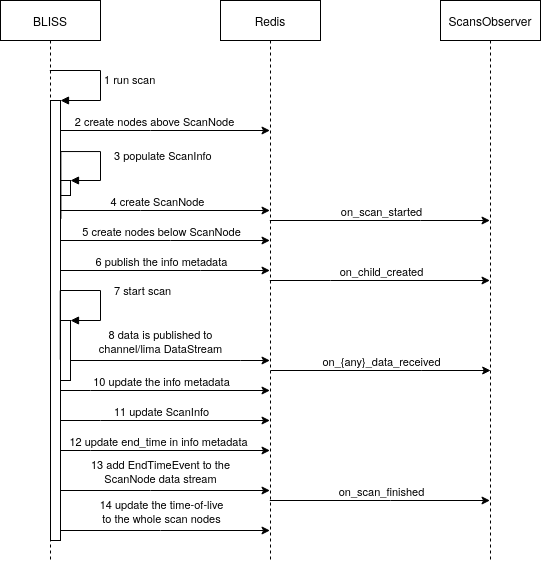
Scan data subscribing¶
Fetching scan data of a finished or ongoing scan starts by instantiating a DataNode (or any of its derived classes) and calling walk_events or walk_on_new_events. These generators will yield three types of events (bliss.data.events.walk):
- NEW_NODE: a new node is publish in the scan data tree
- NEW_DATA: new data is published in the data stream of a channel or lima node
- END_SCAN: an end-scan event is published in the data stream of a scan node
There is also walk and walk_from_last which do not yield events but DataNode instances.
When walking a DataNode to receive its events and the events of its children, we need to subscribe to the data streams from which these events are derived:
- the NEW_NODE events are derived from the events in the db_name_children_list streams of
DataNodeContainer - the NEW_DATA events are derived from the events in the db_name_data streams of
ChannelDataNodeandLimaChannelDataNode - the END_SCAN events are derived frm the events in the db_name_data streams of
ScanNode
It is ensured that:
- a NEW_NODE event arrives before any NEW_DATA of that node or any event of the node’s children
- an END_SCAN event arrives after all NEW_NODE and NEW_DATA events associated to that scan
Subscribing to data streams¶
Subscribing to a data stream means adding the db_name of the DataStream to a data stream reader together with a starting stream ID from which we want to start reading the stream events (see bliss.config.streaming.DataStreamReader). The DataStreamReader object reads events from a list of data streams and adds those events to a queue in memory. This can be done in monitoring mode (it only stops reading the streams when we tell it to stop) or in fetch mode (gets all available events and stops). All this happens in a separate greenlet which runs in the backround.
Walking a scan data tree¶
Walking a node is done as follows
- Call
DataNode.walk_on_new_events - Instantiate a
DataStreamReaderwith aDataStreamReaderStopHandleror withwait=False(monitoring vs. fetching mode) - When the node is a
DataContainerNode, subscribe to the db_name_children_list stream - When the node is a
DataContainerNode, search+subscribe to all existing db_name_data and db_name_children_list streams. Filters are applied to exclude unwanted streams (see below). - When the node is a
ChannelDataNode,LimaChannelDataNodeorScanNodesubscribe to the db_name_data stream. - Set the started_event
- Iterate over the event queue of the
DataStreamReaderobject (yield a list of stream events for one particular stream):- Stream events from a db_name_children_list stream:
- Decode/merge events
- For each event:
- When the associated node is a
DataContainerNode, search+subscribe to all existing db_name_data and db_name_children_list streams. Filters are applied to exclude unwanted streams (see below). - Yield a NEW_NODE event
- When the associated node is a
- Stream events from a db_name_data stream:
- Decode/merge events
- Yield a NEW_DATA (
ChannelDataNodeandLimaChannelDataNode) or END_SCAN event (ScanNode). - When the associated node is a
ScanNode, remove all streams of the scan node and its children from theDataStreamReader.
- Stream events from a db_name_children_list stream:
- External call to the
DataStreamReaderStopHandler(monitoring mode) or the event queue is empty (fetching mode) - Stop the
DataStreamReader - Return
DataNode.walk_on_new_events
Stream searching and subscribing is a costly operation for the REDIS server. The walk methods have following filter arguments to reduce the cost:
- include_filter: only events from these nodes are returned (db_name_data streams are not subscribed to but db_name_children_list streams are subscribed to)
- exclude_children: no events will be returned from the children of these nodes (non of the streams of the children are subscribed to)
- exclude_existing_children: same as exclude_children but only applies to initial stream search+subscription (step 3). Defaults to exclude_children when not provided.